CHAPTER THREE
The Resolution Method - in CL
In this chapter, and the next, our concern continues to be with the mark-equivalence of expressions. We will present a new way of proving that an expression is mark-equivalent, which (with a little tweak) turns out to be also a method for ascertaining whether or not an expression is mark-equivalent. The method will extend to CLS-expressions, but we start with the far more straightforward case of CL-expressions. The method was invented by John Alan Robinson (following on work of Davis and Putnam) and published in 1965, although it was of course presented in a slightly different context to the present one - there was no explicit talk of circles, letters and subscripts. It came to be called the method of Resolution.
Let E be a CL-expression. Recall that a complete valuation string for E is an expression that contains each of the n letters that occurs in E, just once; and is a product of factors, each of which is either a letter, or a circled letter. Consider the product VE, where V is any complete valuation string for E. V, when put next to E, has the power of 'sucking out' each letter from E, leaving behind either nothing in its place (in case the letter itself is a factor of V), or a mark in its place (in case the circled letter is a factor of V). Thus E is reduced to a C-expression, which can be further reduced to either _ or O. Thus VE is reduced either to V or to O. In the latter case, we say (as in Definition 2.13) that V is 'marked' by E.
Now suppose it is known that for every possible choice of V (all 2n of them),
VE = O ;
then, by Theorem 2.6(b), we know that E itself must be mark-equivalent; that is to say, there exists a sequence of CL-steps that transforms E into the mark O.
What follows is a particular method for finding our way from E to O. It will actually furnish us with a proof that E dominates O; although in this case equality follows easily. (E ≥ O says E = E O, but E O = O by 'delete', therefore E = O.) In other words, the method derives O from E.
The tree of partial valuation strings
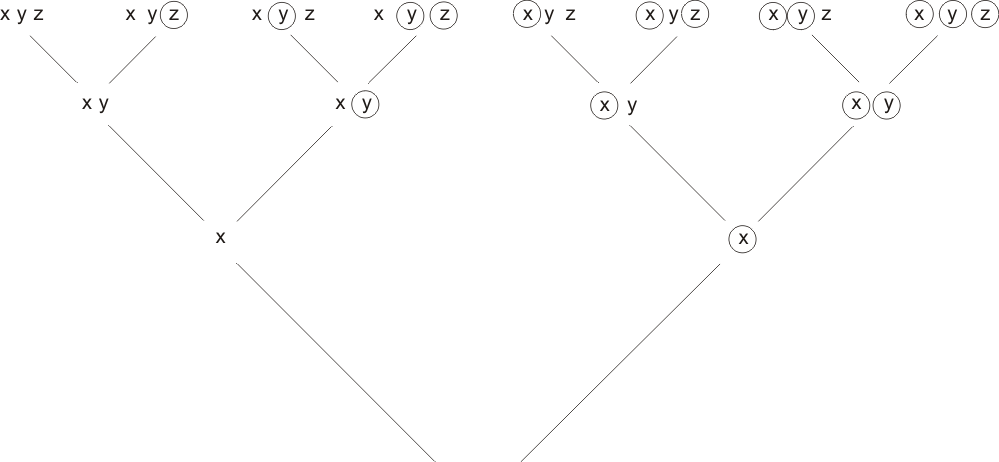
Suppose, for simplicity, that E has n letters occurring in it, and that these letters are
p, q, r, ... x, y, z.
In what follows, the letters could be written in a different order; that would lead to a different, but essentially similar result. The partial valuation strings of length m (with 0≤m≤n) are defined to be all the valuation strings containing the first m letters of the set {p,q,...x,y,z}.
As in Chapter 2 (part 2), the partial valuation strings may be regarded as the nodes of a rooted binary tree, in this case a finite tree whose highest level consists of the nodes (2n in number) of height n. These nodes correspond to the complete valuation strings. The 'parent' of any valuation string is defined to be the string which is identical to the child string except that the last letter (or circled letter) in the string is left off. Each incomplete string has two children, one obtained by adding on the next letter (not so far used), the other by adding on that same letter, circled. The figure shows an example of such a tree, constructed with just 3 letters.
Now suppose that E is composed of a number of different factors:
E = F G ... Q .
Let V be any complete valuation string. It is given that V is marked by E. But this implies that V is marked by at least one of the factors F, G, etc. For V has the power to reduce any of these factors to a primitive value. If the value was _ in every case, then V would not be marked by E after all. Therefore the value must be O in at least one case. Thus to each complete valuation V we may associate a factor of E. (If there are several such marking factors just pick the first that comes to hand.)
We now begin the construction of a second tree, identical in form to the first, but whose nodes will this time consist of CL-expressions. We make the tree from the top down, starting with the top level (height n). We identify each node in this top level with the factor of E that marks the corresponding complete valuation string (i.e. the string occupying the corresponding position in the first tree).
Here is an example, based on the case of an expression with 3 letters. F is the factor which marks the string xyz, G is the factor which marks xy(z), and so on. (Click on the figure to bring up a magnified version.)
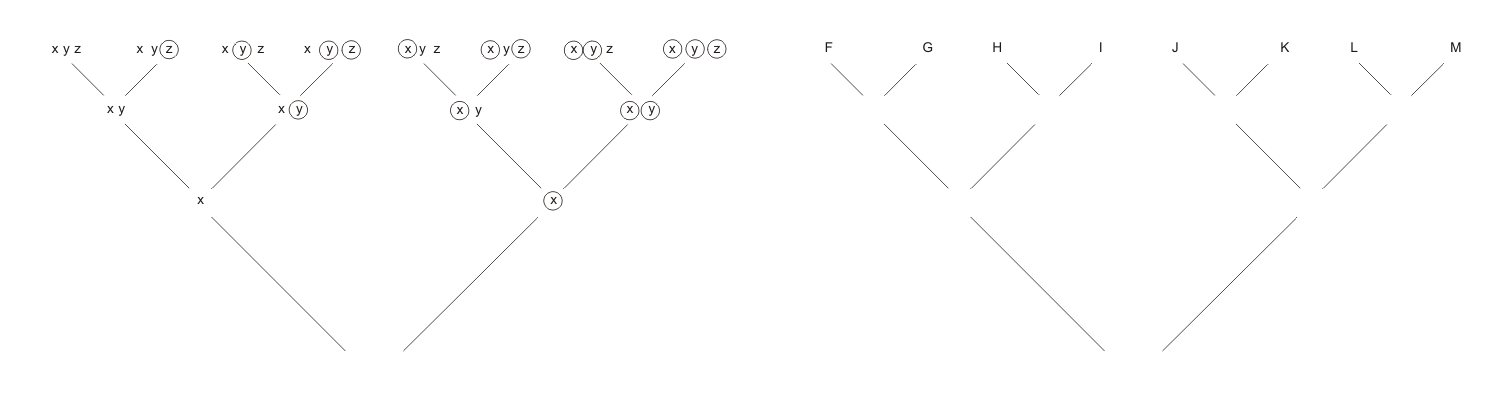
Our next task is to fill in the second-to-top row of the new tree. This will consist, once again, of CL-expressions which mark the corresponding (partial) valuation strings. But we will find that we can also insist that these 2nd level expressions are derivable from their children, i.e. the expressions appearing just above them in the top row of the tree. Perhaps you can already see how that will take us nearer to our goal (of deriving O from E)? If not, all will be revealed in due course.
Growing the Derivation-Tree
Consider two sibling-nodes from the top row of the first tree (the tree of partial valuations). Sibling-nodes have the same parent. The corresponding strings have the form
Uz and U(z),
where z is the last (or nth) letter in the set of letters appearing in E, and U is a partial valuation string of length n-1 (containing all the letters except z). U is the string corresponding to the parent node of the two siblings. Suppose that Uz is marked by expression A, U(z) is marked by B (where A and B are factors of E). So
UzA = O, U(z)B = O.
Now, we seek an expression R derived from A and B, not containing the letter z, and having the power of marking U. (We here use the word 'derived' in the technical sense, meaning that AB is equivalent to ABR.)
Lemma 3.1 Resolution Step
Given two expressions A and B, such that the expression Ut is marked by A, and such that U(t) is marked by B, let At signify the expression that is obtained from A by replacing every occurrence of t in it by the void _ ; and let B(t) similarly signify the expression that is obtained from B by replacing every occurrence of t in it by the mark O. (This notation was introduced in the page on the Case Analysis Lemma.) Let
R = ( (At) (B(t)) );
then
(i) there is no occurrence of the letter t in R
(ii)A B ≥ R
(iii) U R = O.
For the proof we will need a subsidiary lemma:
Lemma 3.2
Let A, B, and t be any expressions; then
( (A) t ) ( (B) (t) ) ≥ ( (A) (B) ).
Proof
This is easy to prove using the necessary and sufficient condition for F≥G, namely F(G)=O, but we here give a direct derivation:
( (A) t ) ( (B) (t) )
= ((A)t) ((B)(t)) (( )) [wrap]
= ((A)t) ((B)(t)) ( ( ) (t) (A) (B) ) [undelete]
= ((A)t) ((B)(t)) ( ((B)(t)) (t(A)) (A) (B) ) [copy, 3 times]
= ((A)t) ((B)(t)) ((A)(B)) [uncopy]
≥ ((A)(B)) [CD dominates D]
◊
Proof of 3.1
Statement (i) is obvious. For (ii):
AB = AB (O) (O) [wrap, twice]
= A B (O t) (O(t)) [undelete]
= A B ((A) t) ((B) (t)) [copy]
≥ ((A) t) ((B) (t)) [CD dominates D]
= ((At) t) ((B(t)) (t)) [uncopy]
≥ ((At)(B(t))) [Lemma 3.2]
= R .
For (iii), we are given that
UtA = O.
Now, in any CL-equation, one may substitute a primitive value ( _ or O ) for a letter, throughout the equation, and by so doing obtain a new equation, which is at least as valid as the original equation. (The reason is that this works OK with the Bricken Initials.) In the equation just given, let us substitute _ for t. The equation becomes:
U At = O.
Similarly, from
U (t) B = O
we obtain
U B(t) = O ,
by substituting O for t. Therefore,
U R = U ((At)(B(t))) = ((UAt)(UB(t))) = ((O)(O)) = O
◊
We call R the 'resolvent' of A and B. Sometimes it will be useful to use the more specific notation
Resx[F,G] = ((Fx)(G(x)))
for the resolvent of F and G with respect to the letter (or expression...) x . Note that Resx[G,F] is different from Resx[F,G]; and that there is nothing to stop us considering the resolvent of an expression with itself, such as Resx[H,H].
Remark 3.3
If the letter t does not actually appear in the expression A, the resolution of A and B is redundant in the following sense. A itself has the properties that R is supposed to have: (i) it does not contain the letter t (ii) it is dominated by AB (iii) it has the power to mark the valuation U. Only (iii) is non-trivial. It is given that
U t A = O ;
substituting _ for t in both sides of the equation, A and U are unaffected; all that happens is that the t disappears, leaving us with
U A = O .
Thus U is marked by A. The same argument applies to B: if t does not appear in B, then B itself will serve instead of the resolvent. If both expressions are t-free, then either will do the trick.
The resolution step gives us a way of working down from the top level of the derivation tree to the next level down. We resolve (with respect to the letter z) each sibling-pair of factors to obtain a new expression which we put in the position of the parent node.
In the new row of expressions (i) the letter z has been eliminated (ii) each node is derived from its children (i.e. the two nodes just above it in the tree) and (iii) each node has the property of marking the corresponding node (a valuation string) in the first tree (the tree of partial valuations).
Evidently there is nothing to stop us going down another level by repeating the procedure - giving us a new row of expressions from which the next-to-last letter, y, say, has been eliminated.
And so on... until we get to the root of the tree. By this time, all the letters will have been eliminated - so the expression at the root must be equivalent to _ or O. But at the same time, it must have the power to mark the corresponding valuation string in the first tree. This is the empty string. Does _ have the power to mark _ ? Certainly not: therefore the C-expression at the root of the derivation-tree must be C-equivalent to the mark. The derivation-tree thus constitutes a derivation of the mark, from the expressions at the top of the tree. These are all factors of our original expression E, therefore the mark can be derived from E, which implies that E is actually equivalent to the mark.
So, what have we achieved? From the premise that all complete valuation strings are marked by E, we have deduced, by a somewhat circuitous route, that E is mark-equivalent. 'Big deal!', you may say - we already knew that from Theorem 2.6(b). But now for the 'tweak'...
The Resolution Method
Suppose we are given an expression E (the product of various factors) of which we don't know whether or not it is mark-equivalent. We may reason as follows. If E is mark-equivalent, then (as just demonstrated) there exists a derivation-tree leading from E to the mark. To actually construct the derivation-tree we would have to go through the whole set of partial valuations (2n of them), verifying that each one of them was marked by E, and finding out which factor of E was responsible. But we don't actually have to construct the derivation-tree to find out whether or not it exists. We may adopt instead what we might call a 'scatter-gun' approach.
We take the factors of E (call them F, G, ... K) and select a letter (z, say). We then form all the resolvents (with respect to z) we possibly can between the various factors; that is, all the expressions
Resz[A,B]
with A and B both running through all the factors of E. (Thus each pair of factors comes up twice in the list: the second time, the order of the factors is reversed. Also, each factor is resolved with itself. If the number of factors is m then the number of resolvents is m².) Now for the beautiful thing: this list of resolvents must contain all the expressions that appear in the second row from the top of the derivation-tree (if there is one). The list doen't tell us anything at all about the order in which the resolvents should be placed in the second row of the tree - it just tells us what the second row is made of.
Next, we eliminate another letter - y, say. We form all the resolvents (with respect to y) we possibly can between the z-less expressions of the second row. Amongst these resolvents must be found all the expressions that can appear in the third row of the tree. And so on: until we obtain a number of expressions containing no letters at all. These, being C-expressions (rather than CL-expressions), can all be reduced to _ or O . If there is a mark among them, then we know that E can indeed give rise to a mark by derivation (implying that E is mark-equivalent). If not, then E cannot be mark-equivalent - because there cannot be a derivation-tree having a mark at its root.
What we have just described is a way of determining whether or not any given CL-expression is mark-equivalent. This is what we call the Resolution Method.
Remark 3.4
Following on Remark 3.3: if E is known to be mark-equivalent, then a derivation-tree can be constructed without going to the trouble of forming resolvents when one or other of the expressions to be resolved does not contain the letter that is being eliminated at any particular stage. That expression can be brought down directly to the next level. The implication for our scatter-gun approach is that at any stage, the expressions which do not contain the letter that is currently being eliminated can be left out of the resolution-between-all-factors and can be taken just as they are to the next level down.
Clausal Resolution
The Resolution Method becomes somewhat more transparent, if, before applying it to an expression E we first get E into what we may call 'clausal form'.
Definition 3.5 Clausal form
Let us say that a CL-expression is a clause if it consists of a valuation string, encircled. And let us say that an expression F has causal form if it consists of a product of clauses.
Lemma 3.6
Any expression is equivalent to an expression that has clausal form.
Proof
We make use of the void-equivalent expression Ωn introduced in Lemma 2.5. (Here n is the number of distinct letters occurring in E, and Ωn is constructed using those letters.) We have:
(E) = (E) Ωn = (E)( (V1) (V2) (V2)... (VN) ) .
Here N is 2n, and the Vi are all the complete valuation strings for E (or for (E)). Transforming the expression by distribute,
(E) = ( ((E)V1) ((E)V2) ((E)V2)... ((E)VN) )
∴ E = ((E)V1) ((E)V2) ((E)V2) ... ((E)VN) .
Now each factor ((E)Vi) is equivalent either to _ or to (Vi). The void-equivalent factors can be left out; then E is equivalent to a product of factors all of the form (Vi), in other words, to a product of clauses. We call this a clausal form for E.
◊
The one that we have found is unlikely to be the most elegant among all the possible clausal forms of E. Recall that a clause is a valuation string with a circle around it. Whenever two clauses differ only in one 'place' i.e. the associated valuation strings are almost the same except that one has (x) where the other has x (for some letter x), they may be merged using the lemma of the CL-calculus (the same that we used in the proof of Lemma 2.5)
(U(x)) (Ux) = (U) .
This reduces the number of clauses by one; and the operation may be repeated as many times as possible. It should be noted that in case E itself is the product of several factors, each factor can be reduced to clausal form first; their product will then be in clausal form automatically.
From now on, let us assume that E is given to us in clausal form; and suppose that we wish to find out whether or not E is mark-equivalent. What happens when we apply the resolution method? The factors of E are now all clauses, so the question is, what is the resolvent of two clauses?
Suppose the two clauses are (U) and (V), where U and V are valuation strings. Then
R = Rest[(U),(V)] = ( ((Ut)) ((V(t))) )
= ( Ut V(t) ) .
Now, if the string U contains the letter t (uncircled), Ut is the same string with t removed: it is still a valuation string, just shorter. If, on the other hand, U contains (t), then Ut is mark-equivalent, and R is void-equivalent. In that case R is no help in deriving the mark, and can be discarded. Similarly, if V contains (t), then V(t) is just a shorter valuation string; but if V contains t (uncircled) then R just vanishes. Also, remark 3.3 still applies: if either U or V is t-free, the resolution step is unnecessary, so we may assume that both strings contain the letter t, one way or another. In summary, the resolution step only produces an interesting result in the case that U contains t, and V contains (t). Now, consider once more the expression
Ut V(t) .
This is a string of letters and circled letters - not including t or (t). That does not quite make it a valuation string, because of the possibility of repeated letters. If a letter, x say, is present (uncircled) in both Ut and V(t), then the two instances of x may reduced to one by uncopy. Similarly if (x) is repeated. But what if one string contains x, the other (x)? The factor x(x) makes the whole string mark-equivalent so R goes up in a puff of smoke. Yet another way in which the resolvent can fail to be interesting! But if there is no such instance (of a letter in one part matched with the same letter circled in the other part), then the string is equivalent to a valuation string, the resolvent to a clause. Thus in all cases the resolvent of two clauses is equivalent either to the void or to a new clause.
If the two clauses are (t) and ((t)), so U=t and V=(t), then Ut and V(t) are both void, and the resolvent is
( Ut V(t) ) = O .
The mark is a perfectly good clause, just as the void is a perfectly good valuation string. So if (t) and ((t)) can be derived by resolution from an expression E, we know we are on the home straight - the very next step will yield the mark.
It can be tiresome to have to write ((t)) when we know very well that this particular clause is equivalent to the simpler expression t. It makes sense to bend the rules and let t, or any other letter by itself, count as a clause. We just have to remember that t resolves with any clause containing t (not t circled) and that the product is simply the clause with t omitted. (We may regard this as an application of plain old uncopy.) Similarly, the clause (t) resolves with any clause containing (t) within its outer circle.
Example 3.7
It is time for a simple example. Let us take for our expression
E = (pr) ((p)(q)) (qr) r .
In strict clausal form, this would be
E = (pr) ((p)(q)) (qr) ((r)) ,
but as explained above, we can get away with treating the single letter r as a clause. To construct the tree of partial valuations let us take the letters of E in the order q, r, p. Then the tree looks like this:
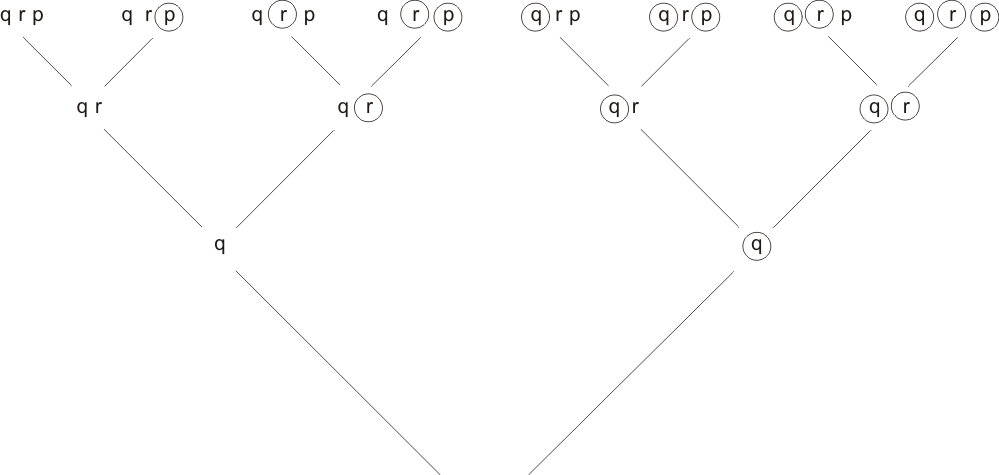
Now, the first of the complete valuation strings, qrp, is marked by the clauses (pr) and (qr). Either of these may be taken as the first clause in the top row of the derivation-tree. Working our way through all eight complete valuation strings we get for the whole top row the clauses,
(pr) (qr) r r (pr) ((p)(q)) r r
(Exercise for the reader: check that each of these clauses marks the corresponding complete valuation string. The fact that each of the valuations can be marked tells us already that E is mark-equivalent.) To get down to the next row, we need to eliminate p. In the first pair of clauses, (pr) and (qr), the second does not include p, so the derived clause is simply (qr). Similarly, the derived clause of the second pair is just r. The third pair requires a true resolution step
(pr) ((p)(q)) → (r(q));
the derived clause of the fourth pair is just r. So we have for our second row down the clauses
(qr) r (r(q)) r.
Next, we eliminate r. The first pair yields by resolution (q), the second, ((q)) = q. Thus the third row of the derivation-tree is
(q) q ;
and the fourth, just O. Here is the complete derivation-tree:
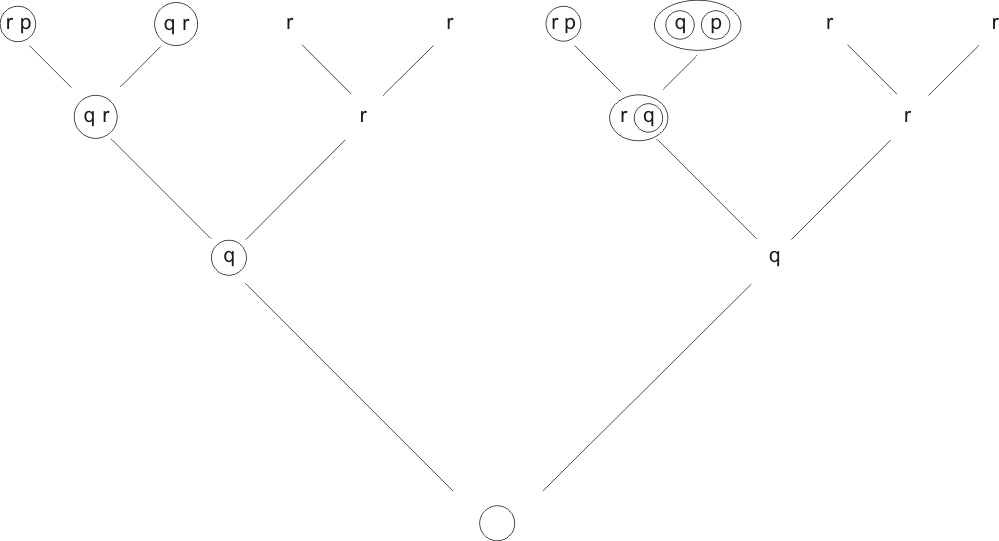
Stratified Resolution
Now let's turn the problem round and suppose that we are given the same expression E and wish to discover (by the resolution method) whether or not it is mark-equivalent. We will record our progress by writing the original clauses, and the ones derived by resolution, in a sequence of layers - a form that is related to the derivation-tree, but less structured. The top stratum consists of the clauses of E, written in a row. In general, we may expect all the letters (in the case of our example, q, r and p) to appear in this stratum.
The next stratum will consist of a set of clauses, in which the letter p does not appear. If p is absent from any clause in the upper stratum, we copy that clause into the lower stratum. If a clause C in the upper stratum contains p (uncircled) we see if we can find any clauses that contain (p). If not, C is left behind in the upper stratum; if so, we take each clause D containing (p) in turn and add the resolvent of C and D to the lower stratum. Repeat the procedure for all clauses containing p. In brief, form the resolvents (with respect to the letter p) arising from all suitable pairs of clauses in the upper stratum.
We then go onto the next stratum down, from which the letter r will have been eliminated. Form all possible resolution products (which eliminate r), and copy all clauses that do not contain r anyway.
Then down to the next stratum, and to the next. This is the result:
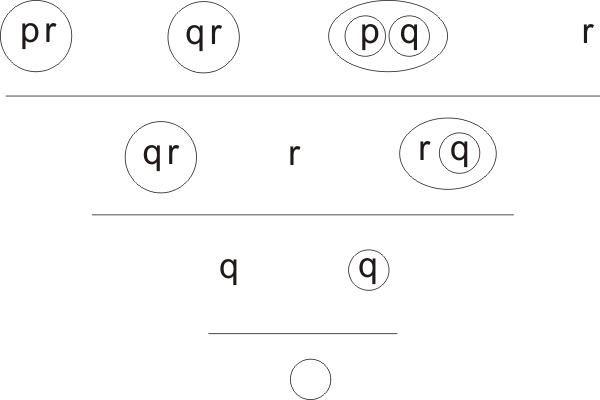
This verifies that E is mark-equivalent; and also shows that the clauses which appear in each row of the complete derivation-tree (last subsection) all appear in the corresponding stratum.
Example 3.8
Let E be the expression
(p(q)r) ((q)(r)) ((p)q) ,
and let us investigate it by eliminating r, q and p in turn. The first stratum down will consist of
(p(q)) ((p)q) ;
eliminating q between these two we get
(p(p)) = _ .
There is no other way of obtaining a q-and r-free clause by resolution, so no way of deriving the mark. We conclude that E is not mark-equivalent.
Pitfall: this does not imply that E is void-equivalent!
Free-Style Resolution
Finally, we can do resolution without bothering about the order of the letters. We can attempt to construct a derivation of the mark as follows. Let the top stratum consist of all the clauses of E. In the next we put all possible resolution-products of pairs of clauses in the top stratum, eliminating any letter. The next stratum down after that consists of resolution products of all pairs of clauses from the higher strata, such that at least one member of the pair belongs to the stratum just above the current one. (The point of this last condition is just to exclude repeats.) And so on... (At each stage we don't bother writing down resolution-products that are not new.)
Returning to the expression used in example 3.8:
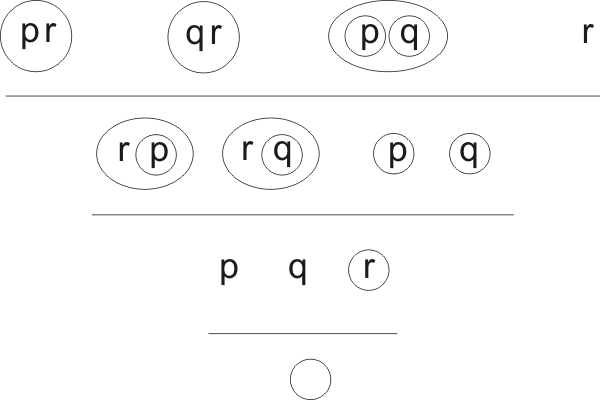
Again, among all the resolvents that are written down, will occur the ones that would occur in a properly ordered derivation-tree - although not necessarily in the correct stratum - so if E is mark-equivalent, O will appear sooner or later in the free-style method. Note that in any case the process of writing down new resolvents must terminate after a finite number of steps - because there is only a finite number of distinct clauses that can be made out of n letters.
How does the process end if E is not mark-equivalent? One ends up with a collection of clauses, from which no new clause can be derived by resolution. The difference is just that the mark is not among them!
Let's sum up what we have just learnt in another theorem:
Theorem 3.9 Resolution in CL
Let E be a CL expression. We may assume without loss of generality that E is in clausal form. Let the clauses of E be subjected to the process of free-style resolution (as described above). The process will terminate either a) in stalemate (no new clauses, no mark among the original clauses or among the clauses produced by resolution) or b) with production of the mark. A necessary and sufficient condition for case b) is that E is mark-equivalent.